我们知道微信公众号的内容比较有价值,原创性的文章比较多,如果能采集微信公众号,那就好了。因此,均益写了一段python代码,用于通过搜狗入口采集公众号的内容。
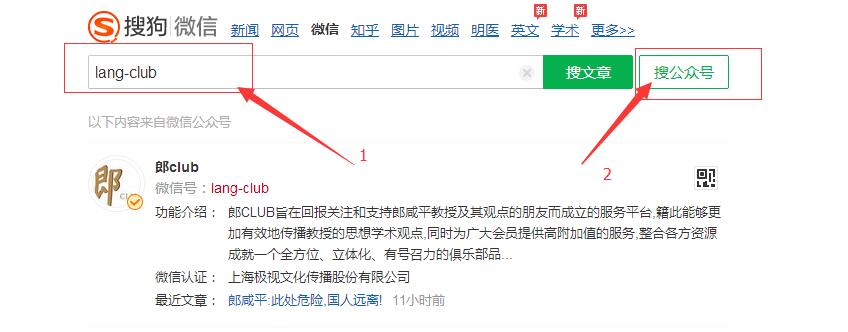
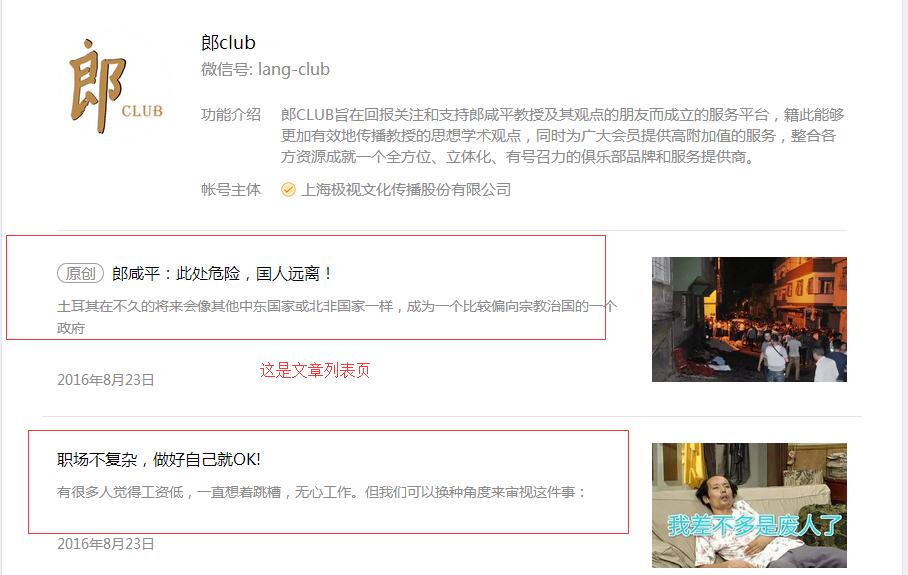
先说一下思路:通过搜狗搜索微信号,获取到这个微信号的文章列表页(现在只显示前面10篇文章),然后通过列表页获取文章页,并采集文章内容。
如图:

实现这个功能的python代码已经写好,里面有注释,相信懂python都能看的明白
#coding:utf-8 #采集搜狗微信 import pycurl,StringIO,json,re,time from lxml import etree def caiji(url): headers = [ "User-Agent:Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36 SE 2.X MetaSr 1.0", "Cookie:m=9E311C74B018D4A8858DF555C61A2E92; IPLOC=CN4403; SUV=00322678777A98C357BB2E859CA75470; usid=2cjwZgHDa8zi4yjB; SNUID=4812F0FD8B8FB1278CDD12588B398BD4; SUID=C3987A773020910A0000000057BB3056; GOTO=Af99046; ABTEST=0|1471886717|v1; weixinIndexVisited=1; sct=2", ] c = pycurl.Curl() #通过curl方法构造一个对象 c.setopt(pycurl.REFERER, 'http://weixin.sogou.com/') #设置referer c.setopt(pycurl.FOLLOWLOCATION, True) #自动进行跳转抓取 c.setopt(pycurl.MAXREDIRS,5) #设置最多跳转多少次 c.setopt(pycurl.CONNECTTIMEOUT, 60) #设置链接超时 c.setopt(pycurl.TIMEOUT,120) #下载超时 c.setopt(pycurl.ENCODING, 'gzip,deflate') #处理gzip内容,有些傻逼网站,就算你给的请求没有gzip,它还是会返回一个gzip压缩后的网页 # c.setopt(c.PROXY,ip) # 代理 c.fp = StringIO.StringIO() c.setopt(pycurl.URL, url) #设置要访问的URL c.setopt(pycurl.HTTPHEADER,headers) #传入请求头 # c.setopt(pycurl.POST, 1) # c.setopt(pycurl.POSTFIELDS, data) #传入POST数据 c.setopt(c.WRITEFUNCTION, c.fp.write) #回调写入字符串缓存 c.perform() html = c.fp.getvalue() #返回源代码 return html def search(req,html): data = re.search(req,html) if data: return data.group(1) else: return 'no' #微信号列表 weiHao = ['lang-club','bazaarstar','duliyumovie'] #以第一个微信号为例 query = weiHao[0] url = 'http://weixin.sogou.com/weixin?type=1&query=%s' % query html = caiji(url) selectors = etree.HTML(html) gongHao = selectors.xpath('//*[@id="sogou_vr_11002301_box_0"]/@href') title = search(r'<title>(.*)</title>',html) print title #采集公众号的文章 url = gongHao[0] html = caiji(url) title = search(r'<title>(.*)</title>',html) #搜狗微信防采集,需要输入验证码,程序将不能正常执行 print title wenKuai = search(r'var msgList(.*)',html) #文章块的js代码 wenUrl = re.findall(r'/s\?timestamp=(.*?)","source_url',wenKuai)#这是文章的URL firsturl = 'http://mp.weixin.qq.com/s?timestamp=%s' % wenUrl[0] #组合成第一篇文章url html = caiji(firsturl) title = search(r'<title>(.*)</title>',html) #文章标题 yuanchuang = search(r'<span id="copyright_logo" class="rich_media_meta meta_original_tag">(原创)</span>',html) #文章是否原创 fabushijian = search(r'<em id="post-date" class="rich_media_meta rich_media_meta_text">([\d-]+)</em>',html) #发布时间 zuozhe = search(r'<em class="rich_media_meta rich_media_meta_text">(.*)</em>',html)#作者 zhengwen = search(r'<div class="rich_media_content " id="js_content">([\s\S]*?)</div>',html)#正文 print title,fabushijian,yuanchuang,zuozhe
虽然能够采集到文章内容了,但是由于搜狗防采集,经常需要更换ip和验证码。均益没有更多ip的,所以不能批量采集。欢迎有ip资源的朋友来测试或者合作。均益还收集了18个分类5万多个公众号的id,想要的朋友也可以联系。
林志超
2016年11月11日 at 上午8:55哎呦,不错哦!欢迎互访
整形频道
2016年10月19日 at 下午1:50不错学习了 谢谢博主
贵阳美贝尔整形医院
2016年10月11日 at 上午9:45感谢楼主的分享,已收藏
工控资料窝
2016年9月10日 at 下午4:57这个不错,很好先收藏了
网赚测评
2016年8月31日 at 下午5:05看看还不错
卢松松博客
2016年8月31日 at 上午11:12很不错,学习了